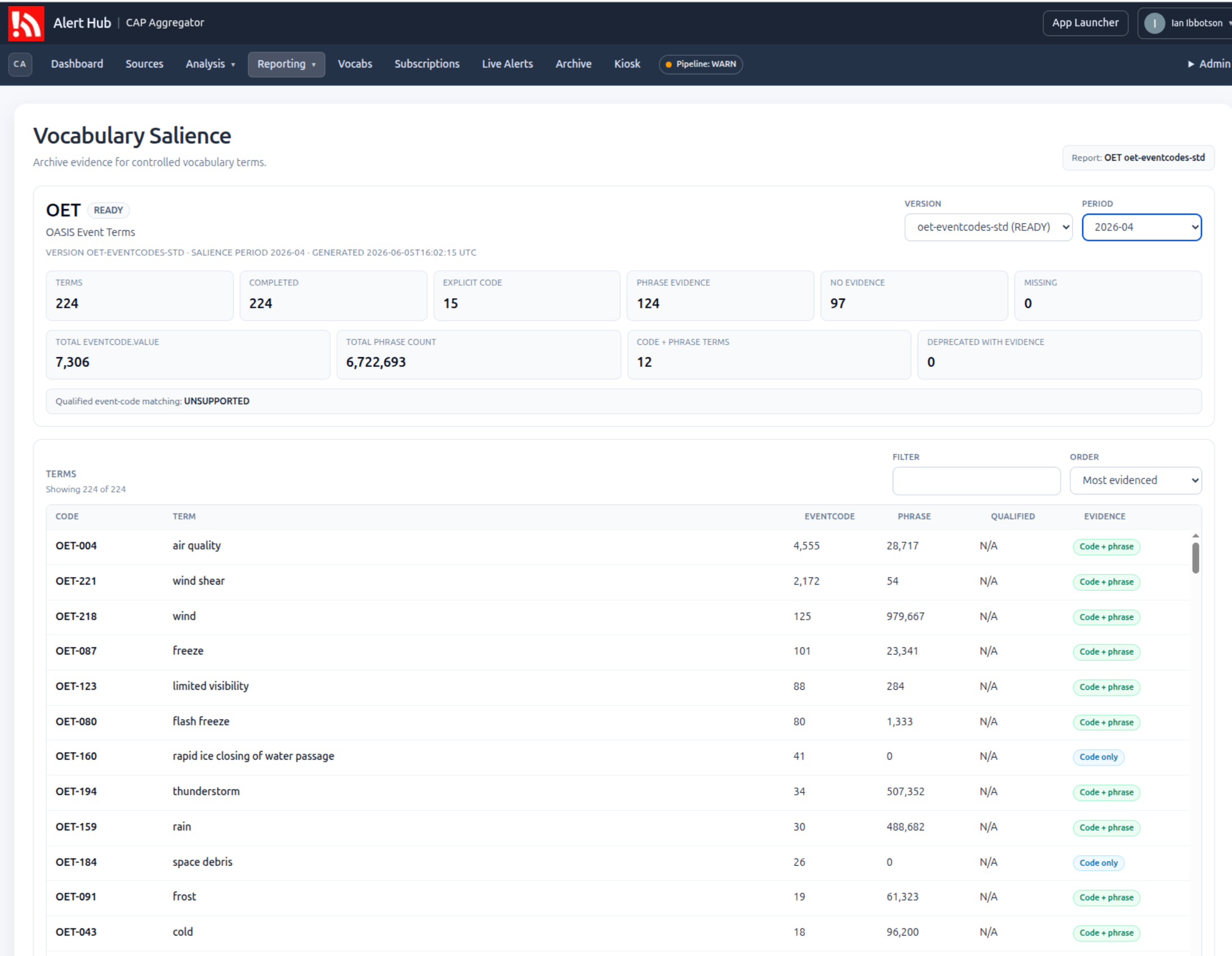
Controlled vocabularies are easier to discuss when there is visible evidence about how their terms relate to real alert traffic.
The latest Alert Hub development slice adds a salience snapshot for each controlled vocabulary term. The intent is modest: provide enough archive evidence to help reviewers ask whether a term is visible in CAP alerts, whether it appears as an explicit event code, and whether the phrase appears in alert text.
What salience means here
The current salience model stores counts for a term against the CAP archive Elasticsearch index:
- the number of archived alerts where
eventCode.valuematches the controlled term code - the number of archived alerts where the preferred label appears as a phrase in
event,headline, ordescription - where the archive mapping safely supports it, the number of alerts where
eventCode.valueandeventCode.valueNamematch inside the same CAPeventCodeobject
The qualified valueName count is deliberately conditional. The archive index is allowed to use its existing natural mapping. If eventCode is not mapped as a nested object, the implementation does not force a mapping change and does not run a loose query that could accidentally combine a value from one event-code entry with a value name from another.
In that case the qualified metric is omitted and the snapshot records that qualified matching is unsupported.
Full archive, monthly snapshot
The snapshot period is an as-of label, not a filter on the count query.
For example, a snapshot recorded for 2026-05 means the salience evidence was generated for that closed reporting month. The Elasticsearch counts themselves are against the full archive, not just alerts from May 2026.
That distinction matters. The current question is not “how often was this term used this month?” It is “what evidence exists across the archive for this term?” Monthly snapshots then let the platform regenerate and compare evidence over time without prematurely narrowing the archive query.
Operator workflow
The admin vocabulary page now exposes the latest salience summary for a selected vocabulary version:
- generated, failed, and missing term counts for the selected snapshot period
- per-term salience details in an expandable section
- a manual “Generate salience” action for the selected version

The scheduled path processes live and ready vocabulary versions. Deprecated terms are included because they may still matter in archive evidence and vocabulary governance discussions.
Failed term snapshots are stored as failed rather than silently ignored. That keeps the retry path simple and makes partial generation visible to an operator.
What remains open
The initial salience model is intentionally small. It does not yet store salience history beyond the monthly snapshot rows, and it does not yet compare explicit vocabulary codes with future automated classification tags.
Those are likely next steps. Once retrospective classification metadata is present in the archive, salience can compare “publisher supplied this event code” with “the classifier would have selected this controlled term.” That comparison could be useful evidence when deciding whether a vocabulary term is too broad, too narrow, duplicated, or missing important synonyms.
For now, the useful test is simpler: can a vocabulary reviewer open a term and see archive-wide evidence for why that term matters?