Emergency alerting already has a strong interoperability foundation in the Common Alerting Protocol, or CAP. CAP gives agencies and systems a shared envelope for public warnings, but the words inside an alert still need careful interpretation: event names, categories, local conventions, synonyms, and operational phrasing all vary across publishers.
Controlled vocabularies are one way to make that interpretation more explicit.
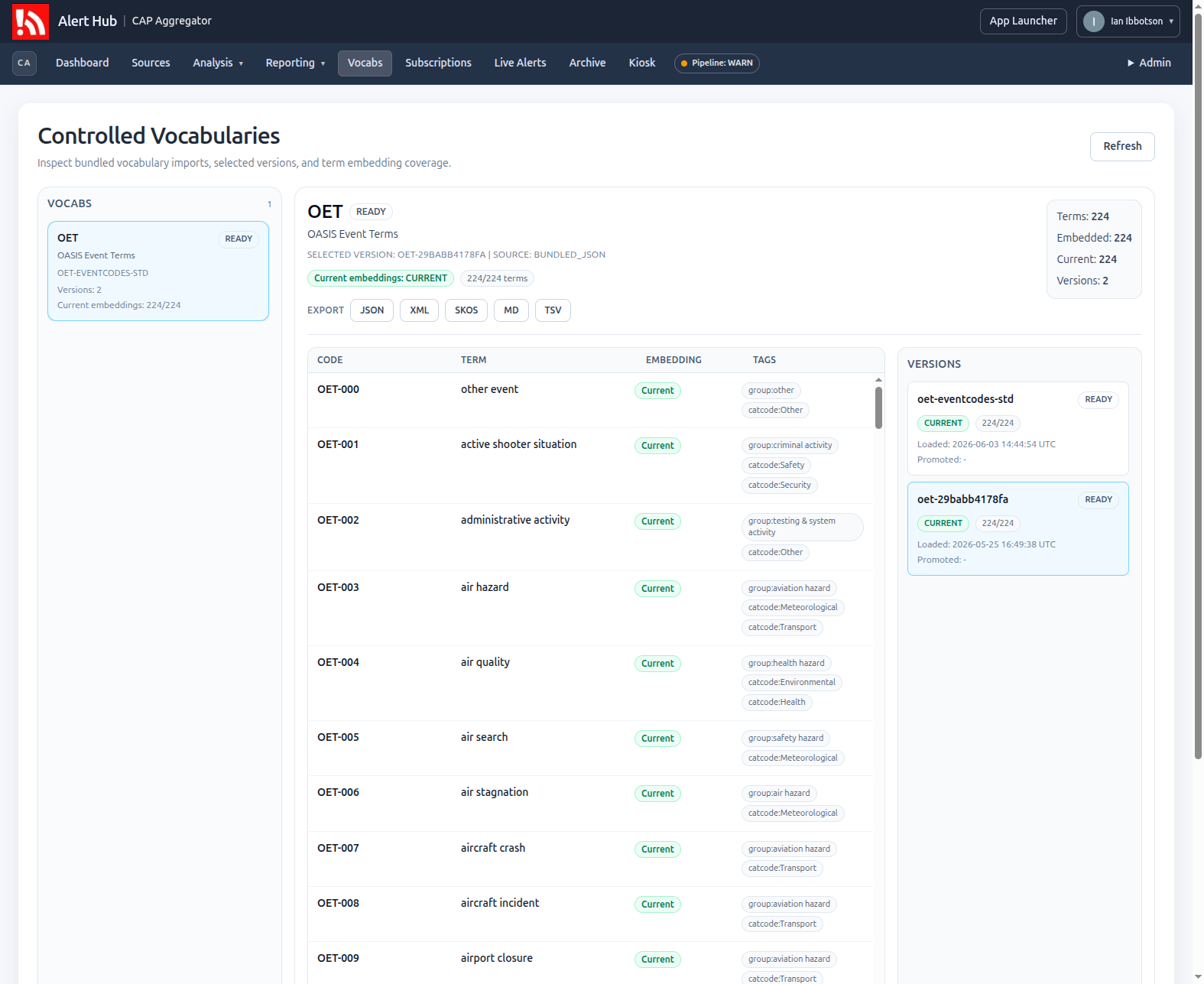
The current implementation treats vocabularies such as the OASIS Event Terms, or OET, as versioned operational data rather than as hard-coded application assumptions. A CAP alert classifier can then point at a controlled vocabulary, classify alerts against a known version, and leave behind enough metadata for another system to inspect the result.
This is still early work. The recent slice adds a practical shape for review: controlled vocabularies can be imported, versioned, embedded, inspected in the admin console, and exported through public download paths.
Why controlled vocabularies matter for CAP
CAP is deliberately flexible. That flexibility is useful for national alerting authorities, weather agencies, emergency management teams, and local operating practices. It also means downstream systems have to normalize meaning if they want to compare alerts across sources.
A controlled vocabulary gives that normalization a stable target.
For emergency alerting, the interesting questions are not only “what did this publisher call the event?” but also:
- which controlled term best represents the alert subject
- which vocabulary version was used
- whether the term was current or deprecated
- what description and usage guidance explain the term
- which embedding model produced the vector used for semantic comparison
- whether another node can reproduce or reuse the same result
The controlled vocabulary work is aimed at making those answers explicit enough to inspect.
The archive problem
Alert Hub also has a time-depth problem. The archive contains more than 15 years of historic CAP alerts, while the OET term list is relatively young. Most alerts in the archive do not carry OET terms, and many older alerts use local event names, spelling variants, compound phrases, or near-synonyms that are useful to analysts but awkward for exact term matching.
The Archive Keyword Explorer was created as one practical response to that problem. It lets an operator compare topics and keywords over time so downstream aggregators and reviewers can see the shape of related language in the archive. A query such as Hurricane Cyclone Typhoon "tropical storm" can show how a related family of terms appears across publishers and years, without excluding alerts simply because they pre-date OET usage or did not include OET terms.

That approach is useful, but it is still term based. It helps answer “where did these strings appear?” better than it answers “which older alerts are probably about the same concept as this controlled term?” For a historic archive, that distinction matters.
CAP XML documents are treaty documents in the operating sense. In the current Alert Hub implementation, the archive work does not rewrite published CAP XML to add vocabulary assignments that were not present in the original alert. What can be added inside Alert Hub is separate metadata about how the archive has been classified, which vocabulary version was used, which method produced the result, and how confident or reviewable that result is.
Embeddings are useful here because they allow retrospective classification to work closer to the conceptual root of a controlled term than a literal keyword list can. In practice, they may make it less likely that an alert is missed because of a misspelling, a regional spelling, a translated phrase, or a local synonym. They may also help with the broader and narrower boundaries that inevitably appear when a vocabulary such as OET is applied to real CAP traffic.
The immediate interest is retrospective analysis of the archive, not automatic rewriting of CAP records. A more tentative future use is suggested terms: prompts that could help CAP authors choose OET terms while they are working under time pressure. The same mechanism may also be relevant to AI-enabled CAP drafting tools, where a system proposes CAP content for human review and includes suggested embedded OET terms as part of the review package. That remains a workflow question, not a claim that the machine becomes the issuing authority.
What changed in this slice
The latest work added a public export surface for vocabulary versions:
/api/v1/public/vocabularies/{code}/versions/{version}/export?format=json
/api/v1/public/vocabularies/{code}/versions/{version}/export?format=xml
/api/v1/public/vocabularies/{code}/versions/{version}/export?format=skos
/api/v1/public/vocabularies/{code}/versions/{version}/export?format=markdown
/api/v1/public/vocabularies/{code}/versions/{version}/export?format=tsvThe admin vocabulary screen now links directly to those exports for each selected vocabulary version. That keeps the operator workflow and public data access close together without making the export mechanism depend on the admin UI.

The structured formats, JSON, XML, Markdown, and SKOS RDF/XML, include embedding information when embeddings are present. That includes the embedding generation key, model details, normalized text, hashes, dimensions, and vectors. TSV deliberately stays lightweight: terms, labels, description, usage, tags, deprecation state, and sort order, but no vectors.
The reason for exporting embeddings is pragmatic. If a group agrees that a term, a normalization process, and a model produce a particular vector, participants can inspect and reuse that value without each system regenerating it independently.
SKOS gives the vocabulary a semantic web shape
The new SKOS export is intentionally separate from the custom XML export.
Custom XML is useful when a system wants a straightforward Alert Hub vocabulary document. SKOS is useful when a system wants to treat the vocabulary as semantic web data.
In the SKOS output:
- a vocabulary version is represented as a
skos:ConceptScheme - each term is represented as a
skos:Concept - the term key is represented as
skos:notation - the preferred label is represented as
skos:prefLabel - description maps to
skos:definition - usage guidance maps to
skos:scopeNote - embedding metadata is carried in Alert Hub extension properties
That gives this CAP and OET vocabulary work a semantic web form that can be inspected with search, linking, graph tooling, and future collaboration in mind.
Description and usage are now first-class term fields
This slice also added two optional term-level fields:
description: a short explanation of what the term meansusage: implementation guidance about when the term is intended to be used
There is not much content for those fields yet. That is deliberate. The immediate goal is to make room for collaboration.
The intent is that people can export a vocabulary, add or improve descriptions and usage notes, and share that work back in a form that could become a future vocabulary version. The fields are present in all export formats so they can travel through review tools, scripts, spreadsheets, and semantic web pipelines.
The embedding text also now includes description and usage when they are present. The expectation is that this can make semantic matching better aligned with the context a human reviewer sees, although this still needs more real-world evaluation.
OET is data, not a hard-coded domain boundary
One cleanup that came out of the same work was naming.
OET is an important vocabulary for the current emergency alert classification path. The implementation treats it as vocabulary data rather than as a hard-coded domain concept inside the platform. The importer code was renamed from OET-specific names to event-code vocabulary names:
OetVocabularyImportServicebecameEventCodeVocabularyImportServiceOetVocabularyBootstrapPropertiesbecameEventCodeVocabularyImportProperties- the internal
OetSourceTermrecord becameEventCodeSourceTerm
The actual OET vocabulary code, term keys, and bundled descriptor remain as OET data. The distinction matters: OET receives careful treatment as data, while the architecture remains open to other CAP-adjacent controlled vocabularies.
Working Direction
The broader implementation direction being explored here is vocabulary-aware alerting infrastructure:
- CAP alerts remain the canonical alert payload
- historic CAP alerts remain unmodified, with retrospective classifications attached as Alert Hub metadata
- controlled vocabularies provide stable classification targets
- vocabulary versions make results auditable
- embeddings make semantic matching practical
- public exports make vocabulary data shareable
- SKOS gives the data a semantic web form
- suggested terms may become a review aid for authors and CAP drafting tools, while final alert content remains a human and institutional responsibility
This is not finished product polish, and it is not a claim that the vocabulary model is complete. The immediate outcome is that the pieces are visible enough to test against real workflows.
The next likely refinements are practical ones: better editor workflows for description and usage text, cleaner vocabulary import adapters, more complete public documentation for export schemas, clearer archive-classification metadata, and real screenshots from the console once the information design has settled.
Verification
The backend test suite passed after these changes:
270 tests, 270 passedThe vocabulary workbench test suite and production build also passed:
85 tests, 85 passed
rspack build passedThe usual rootless Testcontainers cleanup warning still appears after successful backend test completion, but it does not fail the Gradle build.